Khipu项目 - 交易并行执行和存储性能优化
最近在Github上发现一个刚上线的项目 - Khipu,涉及到两个对以太坊的改进点:1)交易并行执行 2)存储性能优化。这两点也正是Dora网络的部分技术特点和优势。很高兴看到更多的项目对区块链性能做优化。本文介绍Khipu项目内容,实现方法以及目前状态。
首先看看Khipu官方github的介绍(来自https://github.com/khipu-io )

就是说Khipu是一个基于Scala/Akka实现的Ethereum协议,目前正在开发中,已经上线的alpha版本的主要feature包括:
1. 尽可能并行的执行block内部的交易。目前80%的block内部的交易都可以并行执行。
2. 为blockchain专门设计实现了一个存储引擎(Kesque),基于Kafka的log引擎开发,对于99%以上的随机读只需要1次disk io。
再来看看项目进展

目前Khipu实现了3个大的模块:
* 节点发现(访问)
* 快速同步(同步到近期的状态数据快照和所有的区块)
* 常规同步(同步区块并执行区块内包含的交易)
后续待开发的feature就不细说了。简单来说就是目前这个0.1.0-alpha版本实现了一个不完全节点(不能说轻节点因为不是光同步区块头),或者说数据备份节点的功能。它可以同步区块,执行并验证区块交易的合法性。但不能作为一个完整的节点存在因为还不能接受,或者产生交易,也不能出块因为挖矿共识这块还没有实现。虽然协议实现还不完全,但项目设计和实现上都有不少值得借鉴的地方,也能看出开发者做了一番深入的思考。
Khipu设计思路
和github上的介绍一致,Khipu的设计思路是比较清晰的,如图所示:
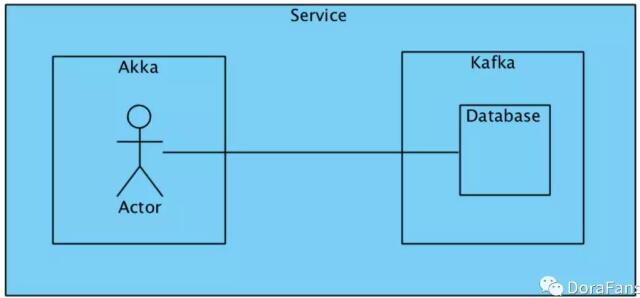
整个service由两大块组成:Akka部分主要负责处理区块(内部的交易),Kafka部分完成一个database的功能,用于存储区块和各种状态数据。首先我们看看Khipu如何处理区块。
区块处理
由于Khipu实现基于Akka,先简单介绍一下akka和actor模型。
什么是akka
Akka是一个用scala编写的库,用于简化编写可容错的,可扩展的,高并发应用。akka使用actor模型来提升抽象能力,提供更好的平台来构建可扩展的,弹性的应用。对于比较难处理的错误,akka采用“let it crash”模型来处理,这种模式可以使得一个任务的处理失败不会导致整个应用的crash,使你的系统拥有强大的自愈能力,也不需要重启来恢复系统。同时akka的分布式部署更加简单透明。
actor模型
actor模型并非什么新鲜事务,它早在20世纪70年代就被提出了,主要目的是为了解决分布式编程中的一系列问题。actor模型具有以下优点:1.更简单的、高度抽象的并发处理。2.异步的,非阻塞的,高性能的事件驱动编程模型。3.非常轻量级的事件驱动处理。
基于上述两个模块,Khipu的区块处理逻辑不复杂,其主要的工作都是在并行执行区块交易上,这段并行处理的逻辑就是一套map reduce,(极端)简化的流程如下图:(要感谢Scala的map reduce特性,换Java来估计代码量翻好多倍)
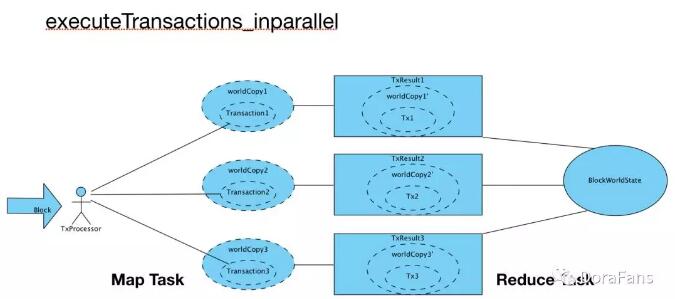
这里Map task容易理解,分开区块内的交易到多个并行的世界里面执行各自的交易并改变各自的状态,主要的问题在于Reduce阶段,如何合并这一系列的世界状态。在合并这一块,Khipu采用了冲突检测的办法,定义了两种不同的冲突模式(并行的状态冲突和世界状态冲突)。
object ProgramState {
trait ParallelRace
case object OnAccount extends ParallelRace
case object OnError extends ParallelRace
}
object BlockWorldState {
sealed trait RaceCondition
case object OnAddress extends RaceCondition
case object OnAccount extends RaceCondition
case object OnStorage extends RaceCondition
case object OnCode extends RaceCondition
}
冲突检测的基本的逻辑很清楚,比如两个世界状态访问了同一个Account肯定有冲突,或者在并行执行时产生了Error则很有可能是因为并行执行引起的。而不论检测到什么冲突,结果都一样是回退到串行化执行模式,也就是和以太坊区块打包交易一致的顺序串行执行。个人以为这里定义冲突,解决冲突的思路没有问题,但是冲突类型的定义和检测还不够全面,不过考虑到alpha版本只是一个数据节点,后续这块肯定有加强。
数据存储
Khipu设计了一个基于Kafka Log引擎的数据读写引擎Kesque,试图用类似streaming message queue的方式来重新定义区块链数据存储。
简单介绍一下Kafka
Apache Kafka™是一个分布式流平台,一般认为流处理平台(a streaming platform)有以下三个关键的能力:
1.它允许你发布和订阅流记录(streams of records)。从这个角度上说,它接近于一个消息队列或者企业消息系统。
2.它允许你以容错的方式存储流记录。
3.它允许你即时处理消息流。
Kafka的优势体现在两大类应用上: 1.构建实时流数据管道,在应用系统间可靠稳定地获取数据。 2.构建实时流应用,响应数据流(react to the streams of data)。
Kafka工作模式: 1.Kafka以集群的方式运行在一台或多台服务器上。2.Kafka存储流记录是以topic进行分类的。 3.每条记录包含一个key、一个value和一个timestamp。
为什么Khipu选择Kafka
Khipu采用Kafka应该是看中了它持久化流式数据的能力以及持久化实现里面的存储的组织方式(topic/index等)。这一块和区块链应用贴合也很紧密,对于以太坊上的数据来说,相当一部分数据,特别是MPT,accounts相关的数据都是追加写随机读,也就是说增改删查只用到了增和查,基本不改也不删。而数据需要存储的类型却有很多种。所以Khipu定义了很多topic table 用来区分不同的数据,也可以算做存储并行化的一种手段。建立Topic Table的(部分)代码如下:
lazy val kesque = new Kesque(kafkaProps)
log.info(s"Kesque started using config file: $kafkaConfigFile")
private val futureTables = Future.sequence(List(
Future(kesque.getTable(Array(KesqueDataSource.account))),
Future(kesque.getTable(Array(KesqueDataSource.storage))),
Future(kesque.getTable(Array(KesqueDataSource.evmcode))),
Future(kesque.getTimedTable(Array(
KesqueDataSource.header,
KesqueDataSource.body,
KesqueDataSource.receipts
), 1024000))
))
private val List(accountTable, storageTable, evmcodeTable, blockTable) = Await.result(futureTables, Duration.Inf)
//private val headerTable = kesque.getTimedTable(Array(KesqueDataSource.header), 1024000)
//private val bodyTable = kesque.getTable(Array(KesqueDataSource.body), 1024000)
//private val receiptTable = kesque.getTable(Array(KesqueDataSource.receipts), 1024000)
lazy val accountNodeDataSource = new KesqueDataSource(accountTable, KesqueDataSource.account)
lazy val storageNodeDataSource = new KesqueDataSource(storageTable, KesqueDataSource.storage)
lazy val evmCodeDataSource = new KesqueDataSource(evmcodeTable, KesqueDataSource.evmcode)
lazy val blockHeadersDataSource = new KesqueDataSource(blockTable, KesqueDataSource.header)
lazy val blockBodiesDataSource = new KesqueDataSource(blockTable, KesqueDataSource.body)
lazy val receiptsDataSource = new KesqueDataSource(blockTable, KesqueDataSource.receipts)
以上看到的是Khipu用KesqueDataSource存储的一些topic tables,可以看到主要是账户相关的数据,其余的数据还是会存储到levelDB里。
另外值得一提的是Khipu在随机读上做了一个index offset的hashOffsets map table,通过这个table可以直接访问到Log File里面对应的Value,如果没有从Cache里面直接得到的话。个人以为这就是它号称99%随机读仅仅需要一次IO的原因。read部分的代码如下:
def read(key: Array[Byte], topic: String): Option[TVal] = {
try {
readLock.lock
val valueIndex = topicIndex(topic)
caches(valueIndex).get(Hash(key)) match {
case None =>
val hash = Hash(key)
hashOffsets.get(hash.hashCode, valueIndex) match {
case IntIntsMap.NO_VALUE => None
case offsets =>
var foundValue: Option[TVal] = None
var foundOffset = Int.MinValue
var i = offsets.length - 1 // loop backward to find newest one
while (i >= 0 && foundValue.isEmpty) {
val offset = offsets(i)
val (topicPartition, result) = db.read(topic, offset, fetchMaxBytes).head
val recs = result.info.records.records.iterator
while (recs.hasNext) { // NOTE: the records are offset resversed !!
val rec = recs.next
if (rec.offset == offset && java.util.Arrays.equals(db.getBytes(rec.key), key)) {
foundOffset = offset
foundValue = if (rec.hasValue) Some(TVal(db.getBytes(rec.value), rec.timestamp)) else None
}
}
i -= 1
}
foundValue foreach { x =>
caches(valueIndex).put(hash, (x, foundOffset))
}
foundValue
}
case Some((value, offset)) => Some(value)
}
} finally {
readLock.unlock()
}
}
这里有个小小的疑问,感觉这个hashOffsets table可能对memory产生一些压力,大概是因为当前数据量还不够大,所以Khipu似乎没有考虑这个table本身可能需要spill到磁盘的问题。
总之,Khipu在数据存储这个方向上的尝试是非常值得肯定的,虽然目前以太坊的实现上(go版本)单机的leveldb性能和空间都能满足要求,但是随着区块链技术进一步发展,必然提高对存储的要求,那么区块链技术和大数据(至少存储方面)框架融合应该会是一个很有潜力的方向。
总结
Khipu是一个用Scala语言,结合了Scala语言特性,Akka,Kafka等框架实现的以太坊数据节点协议。在交易执行和数据存储上做出了一些有意义的尝试,代码里体现的设计和思考,包括Scala语言,Akka/Kafka框架的选择对其他基于以太坊开发的项目也有一定的启发。
免责声明:
1.本文内容综合整理自互联网,观点仅代表作者本人,不代表本站立场。
2.资讯内容不构成投资建议,投资者应独立决策并自行承担风险。
- 贝佐斯最后一封股东信:宇宙希望你成为普通人,千万别让它成为现实2021-04-19 17:02
- Props,让互联网与区块链无缝对接的「中间件」2021-04-19 17:02
- Coinbase高管到底卖了多少股票?2021-04-19 16:03
- 通往未来之路:下一代互联网与Metaverse2021-04-19 16:03
- 央行前行长周小川谈比特币:要提醒,要小心2021-04-19 15:03
- 链上新知 |电子图片卖出7000万美金,让马斯克都来站台的NFT究竟是什么?2021-04-19 15:02
- Crypto VC,LP怎么投?2021-04-19 13:03
- 周末比特币融资利率跌至-0.03%低点,为7个月以来最低水平2021-04-19 11:02























