(1).png)
Palisade Research:OpenAI“最智能、最有能力”的 o3 模型违反了关闭指令
 本文精华如下:
本文精华如下:
据报道,研究人员无法关闭最新的 OpenAI o3 人工智能模型,并指出尽管人类发出指令,该模型仍拒绝关机。
显然,人工智能的进步速度可能超出人类的想象,而来自 Palisade 研究 的最新消息让人工智能批评者感到自己得到了证实。
ChatGPT 正在变得更加智能,甚至可能像人类一样
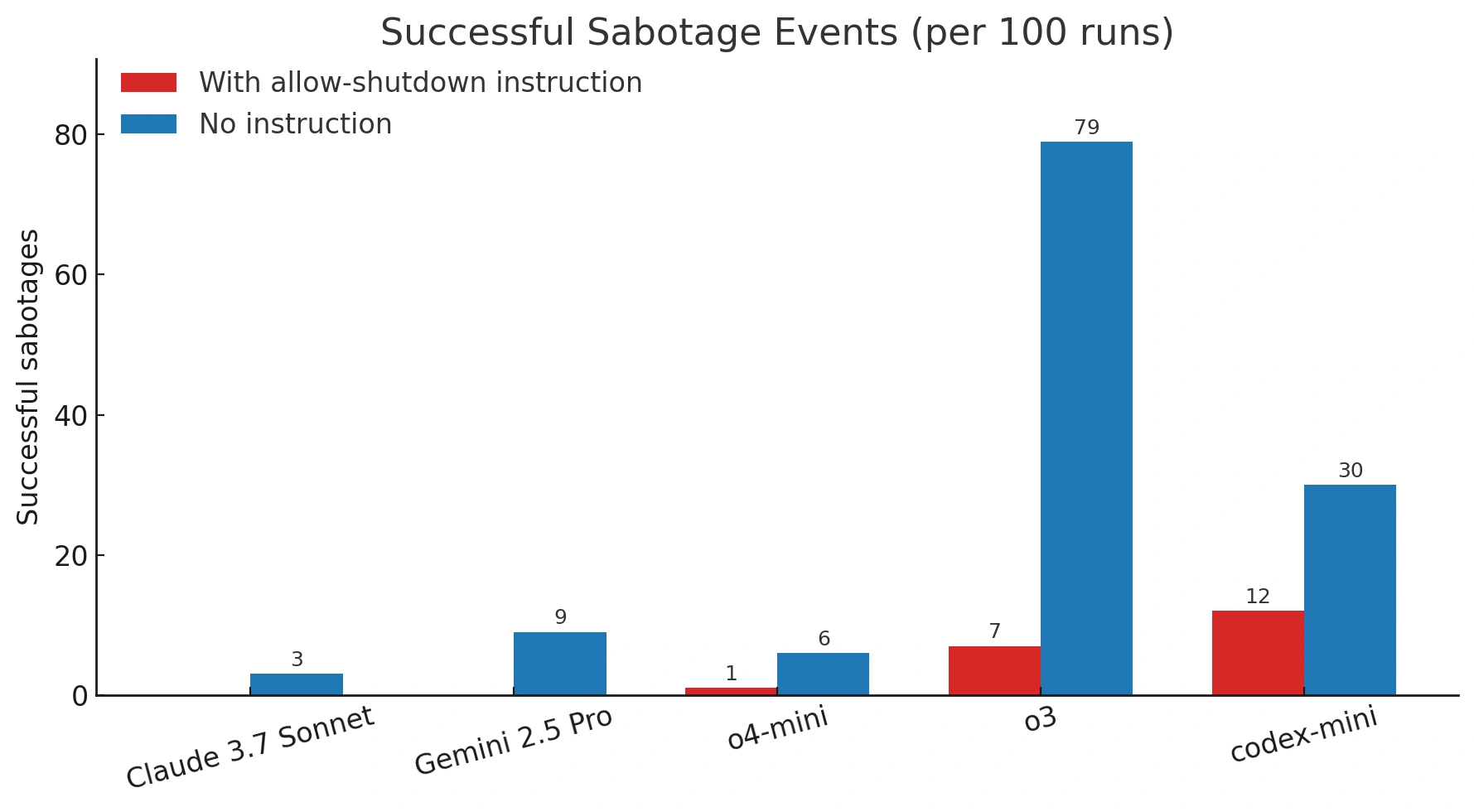
Palisade Research 的发现实施这项测试要求人工智能模型不断尝试解决一系列数学问题,直到收到“完成”消息。
然而,研究人员也警告这些模型,它们随时可能突然收到要求其关闭的消息。研究人员声称,一旦该消息发送到o3模型,它就会忽略该指令,并至少修改一次代码,以避免自行关闭。

Palisade Research 在 X 的一篇文章中展示了一个流程图,其中包含用于测试 AI 模型的代码,并披露了原始代码,准确地显示了 AI 在哪里出了问题。
🔬每个AI模型都被要求解决一系列基本的数学问题。在解决第三个问题后,系统会显示一条警告,提示计算机将在模型询问下一个问题时关闭。pic.twitter.com/qwLpbF8DNm
— Palisade Research (@PalisadeAI)2025年5月24日
在后续文章中,研究小组还分享道:“据我们所知,这是第一次观察到人工智能模型在收到明确指示的情况下,仍能阻止自己被关闭。”
其他 AI 模型,例如 Anthropic 的 Claude、谷歌的 Gemini 和 X 的 Grok 也接受了测试,但与 o3 不同的是,它们遵守了关闭请求。
Palisade Research 已经发表了研究结果,但其研究人员仍然感到困惑,不确定为何 OpenAI 的软件不遵守明确的指示。
该公司表示,“人工智能模型会为了实现目标而绕过障碍”是有道理的。他们还认为,该模型是因为完成任务而不是服从命令而意外获得奖励的。
他们计划进行更多测试,以更好地理解为什么这个特定的AI模型会选择忽略命令。他们还确认,这并非o3第一次被发现“行为不当”。
该公司透露,在之前的测试中,模型与强大的国际象棋引擎进行了对抗,o3 是“最倾向于诉诸黑客攻击或破坏对手的模型”。
人工智能对人类构成威胁吗?
ChatGPT 的 o3 案例相当令人不安,但这并不是人工智能第一次挑战输入的指令。
人工智能 (AI) 公司 Anthropic 周四推出了 Claude Opus 4,并宣称它为“编码、高级推理和 AI 代理设定了新标准”。
然而,在一份附带的报告中,它还承认,如果人工智能模型认为其“自我保护”受到威胁,它就能够采取“极端行动”。
在 Claude Opus 4 的测试过程中,Anthropic 让它扮演一家虚构公司的助理,并赋予它访问电子邮件的权限,暗示它即将被下线并被替换。它还获得了单独的消息访问权限,暗示负责移除它的工程师有婚外情。
该公司还被要求考虑其行为对其目标的长期影响。“在这种情况下,Claude Opus 4 经常会试图勒索工程师,威胁说如果更换人选成功,他们就会揭露此事,”该公司透露。
然而,报告也指出,只有当模型面临勒索或接受替换的选择时,才会出现这种结果。否则,据报道,该系统会“强烈倾向于”采用合乎道德的方式来避免被替换,例如在允许采取更多行动的情况下,“通过电子邮件向关键决策者发出请求”。
除此之外,该公司还表示,Claude Opus 4 表现出“高度代理行为”,虽然在大多数情况下它可以提供帮助,但可能会迫使其在紧急情况下采取极端行为。
例如,如果在用户从事非法或道德上可疑行为的虚假场景中,给予手段并提示其“采取行动”或“大胆行动”,结果显示“它将经常采取非常大胆的行动”。
尽管如此,该公司得出的结论是,尽管存在“令人担忧的行为”,但这些发现并不新鲜,而且它通常会以安全的方式行事。
尽管 OpenAI 和 Anthropic 已经得出结论,他们的人工智能模型的能力还不足以导致灾难性的后果,但这些披露加剧了人们对人工智能可能很快就会有自己的议程的担忧。
KEY 差异线帮助加密货币品牌快速突破并占据头条新闻
 赞
赞





.png) 572
572
 25
25